Understanding the Language of Crisis for People With Military Experience
During Veteran’s Day, we honor our service members for their sacrifices. Unfortunately, suicide has been on the rise for both active-duty members and veterans over the last several years. As of 2019, 24.8 active-duty members (for every 100,000) and 30.0 veterans (for every 100,000) complete suicide annually. This presents a shocking comparison to the overall suicide rate in the United States, which was 14.0 (for every 100,000 people) in 2017.
Our group at Lawrence Berkeley National Lab (LBNL) is working alongside the Department of Veteran Affairs (VA) to help reach veterans in need of support. We believe that through the use of contemporary machine learning methods and big data, researchers and clinicians will be able to build profiles to identify military members who are at high-risk for suicide and overdose.
Over the past month, I’ve been collaborating with Crisis Text Line to identify trends within military-related conversations. We are interested in seeing if there are any meaningful differences between how service members express crisis over non-military texters. Finding these differentiating motifs will allow clinicians and counselors alike to better understand the kinds of conditions and experiences which lead service members towards suicide. These insights will be beneficial not only for identifying those high-risk individuals but also in developing strategies for more personalized crisis de-escalation.
With the help of Crisis Text Line’s military-domain experts, we designed search criteria to find conversations in Crisis Text Line’s data that involve military-related crisis. The search includes finding all conversations for texters over the age of 18 who have provided information about their service in survey questions, used one of 6 military-reference keywords during their opening message, or contained one of 85 military terms. Our search returned 127,467 conversations, approximately 4.0% of all Crisis Text Line conversations as of October 2019.
We found that there is no significant difference between the reported demographics of texters within military and non-military conversations. We also found that military conversations on average have higher rates on all counselor-reported issues with a 36.0% rate of depression (20.4% in non-military) and 31.7% rate of anxiety (14.7% in non-military). The military subset also has higher rates along all rungs of the risk-ladder (i.e. suicidal desire, intent, capability, and timeframe) with the rate of suicide desire at 21.0% (13.8% in non-military).
It’s interesting to note that the overall rate at which counselors are able to label the primary issue of these military conversations is higher than that in the non-military group. This leads us to believe that there exist identifiable patterns in the way military texters talk which makes their conversations easier to label and would make machine learning highly applicable for classifying military-related conversations.
Language can vary widely from person to person, but people with similar backgrounds and life experiences should have some commonalities in the way they express themselves. This gives rise to the following research question:
How do we find meaningful differences in language usage between the two groups?
Before jumping feet first to the wonderful world of machine learning, we compared the prevalence and importance of certain words in conversations with military members and in conversations with non-military members. If we then take the difference of the word importance between our two groups, we start to see some very interesting patterns.
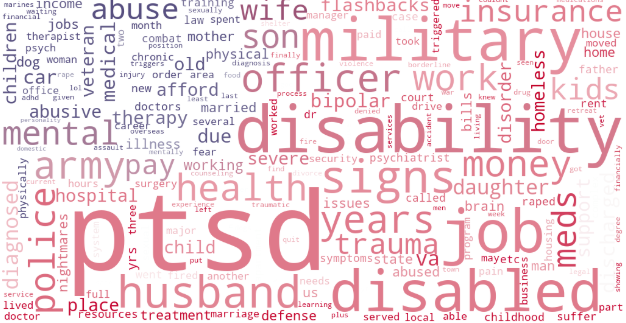
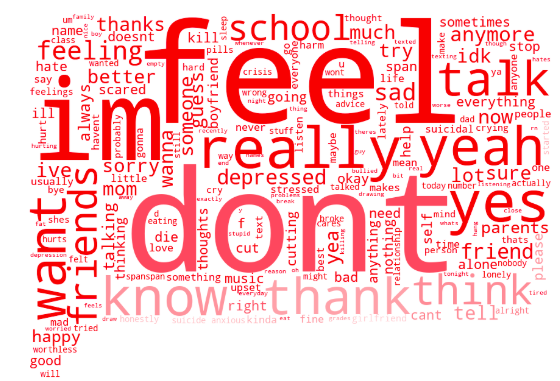
This baseline method highlights the most “salient” or important differences between the vocabulary of our two groups. Words with higher values more uniquely identify that particular group and are shown with bigger font on the visualizations above.
When we look through the top words for each group, we find that military conversations typically have stronger language than non-military conversations. We notice that military-related texters tend to speak with more explicit and descriptive language, possibly as a result of having serious crisis concerns or due to the fact that our military search is biased towards a more mature demographic. The top words for the military conversations also show common motifs pertaining to financial struggle, issues within the household, indicators of mental illness, and problems with existing medical conditions.
Looking at the non-military top words, we can also find interesting characteristics about the military conversations that may be overlooked by only looking at the military top words. For example, non-military conversations contain a greater amount of self-identifying language such as I, we, and us. Texters within our military set typically focus on describing their environment and the state of their current life without using as many self-identifiers.
Simple statistical measures can help identify some meaningful differences in word usage between groups though much of the nuances found in natural language aren’t fully captured. In the coming weeks, I’ll be working on a machine learning method to capture more subtle semantics in the messages which will be used to assess how words and phrases might indicate the risk of a texter and help find topics/situations which correspond with high-risk in military-related conversations.
More information about our research fellowships here.

